Sidekiq vs Resque, with MRI and JRuby
Nov 3, 2012 · 10 min
Before we dive into the benchmarks of Resque vs Sidekiq it will first help to have a better understanding of how forking and threading works in Ruby.
Threading vs Forking
Forking
When you fork a process you are creating an entire copy of that process: the address space and all open file descriptors. You get a separate copy of the address space of the parent process, isolating any work done to that fork. If the forked child process does a lot of work and uses a lot of memory, when that child exits the memory gets free’d back to the operating system. If your programming language (MRI Ruby) doesn’t support actual kernel level threading, then this is the only way to spread work out across multiple cores since each process will get scheduled to a different core. You also gain some stability since if a child crashes the parent can just respawn a new fork, however there is a caveat. If the parent dies while there are children that haven’t exited, then those children become zombies.
Forking and Ruby
One important note about forking with Ruby is that the maintainers have done a good job on keeping memory usage down when forking. Ruby implements a copy on write system for memory allocation with child forks.
1require 'benchmark'
2
3fork_pids = []
4
5# Lets fill up some memory
6
7objs = {}
8objs['test'] = []
91_000_000.times do
10 objs['test'] << Object.new
11end
12
13
14
1550.times do
16 fork_pids << Process.fork do
17 sleep 0.1
18 end
19end
20fork_pids.map{|p| Process.waitpid(p) }
21}We can see this in action here:
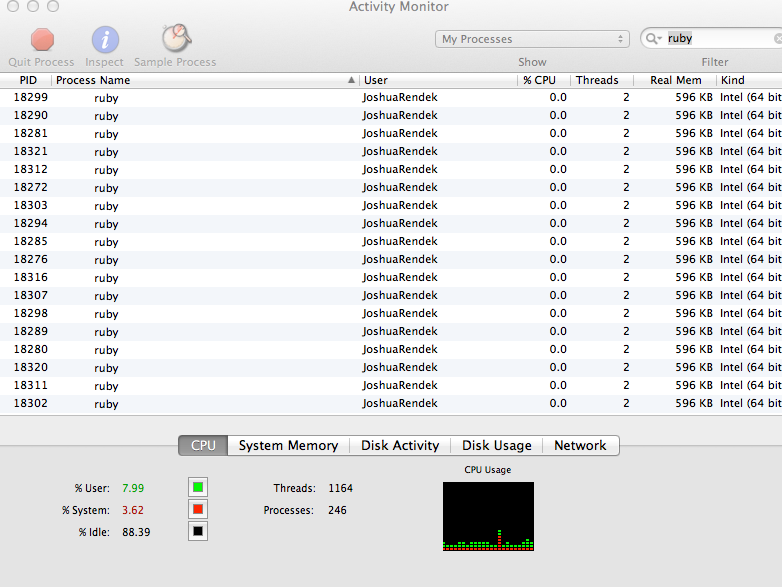
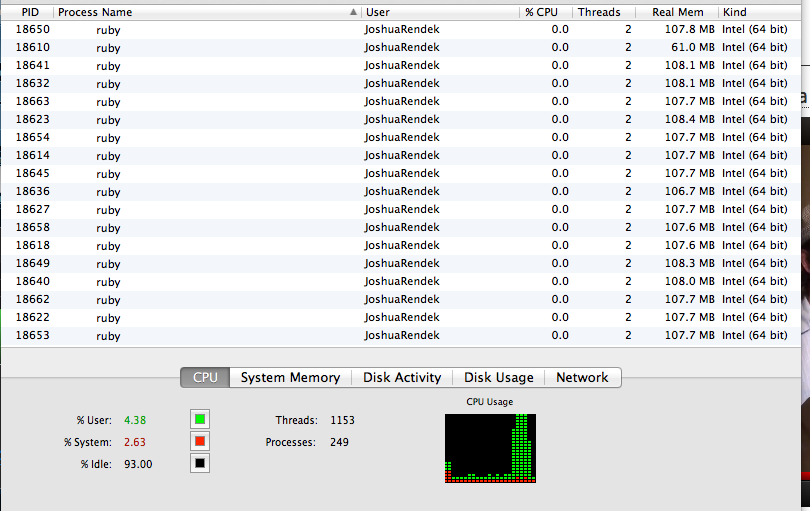
However when we start modifying memory inside the child forks, memory quickly grows.
150.times do
2 fork_pids << Process.fork do
3 1_000_000.times do
4 objs << Object.new
5 end
6 end
7end
8fork_pids.map{|p| Process.waitpid(p) }We’re now creating a million new objects in each forked child:
Threading
Threads on the other hand have considerably less overhead since they share address space, memory, and allow easier communication (versus inter-process communication with forks). Context switching between threads inside the same process is also generally cheaper than scheduling switches between processes. Depending on the runtime being used, any issues that might occur using threads (for instance needing to use lots of memory for a task) can be handled by the garbage collector for the most part. One of the benefits of threading is that you do not have to worry about zombie processes since all threads die when the process dies, avoiding the issue of zombies.
Threading with Ruby
As of 1.9 the GIL (Global Interpreter Lock) is gone! But it’s only been renamed to the GVL (Global VM Lock). The GVL in MRI ruby uses a lock called rb_thread_lock_t which is a mutex around when ruby code can be run. When no ruby objects are being touched, you can actually run ruby threads in parallel before the GVL kicks in again (ie: system level blocking call, IO blocking outside of ruby). After these blocking calls each thread checks the interrupt RUBY_VM_CHECK_INTS.
With MRI ruby threads are pre-emptively scheduled using a function called rb_thread_schedule which schedules an “interrupt” that lets each thread get a fair amount of execution time (every 10 microseconds). [source: thread.c:1018]
We can see an example of the GIL/GVL in action here:
1threads = []
2
3objs = []
4objs['test'] = []
51_000_000.times do
6 objs << Object.new
7end
8
950.times do |num|
10 threads << Thread.new do
11 1_000_000.times do
12 objs << Object.new
13 end
14 end
15end
16
17threads.map(&:join)Normally this would be an unsafe operation, but since the GIL/GVL exists we don’t have to worry about two threads adding to the same ruby object at once since only one thread can run on the VM at once and it ends up being an atomic operation (although don’t rely on this quirk for thread safety, it definitely doesn’t apply to any other VMs).
Another important note is that the Ruby GC is doing a really horrible job during this benchmark.
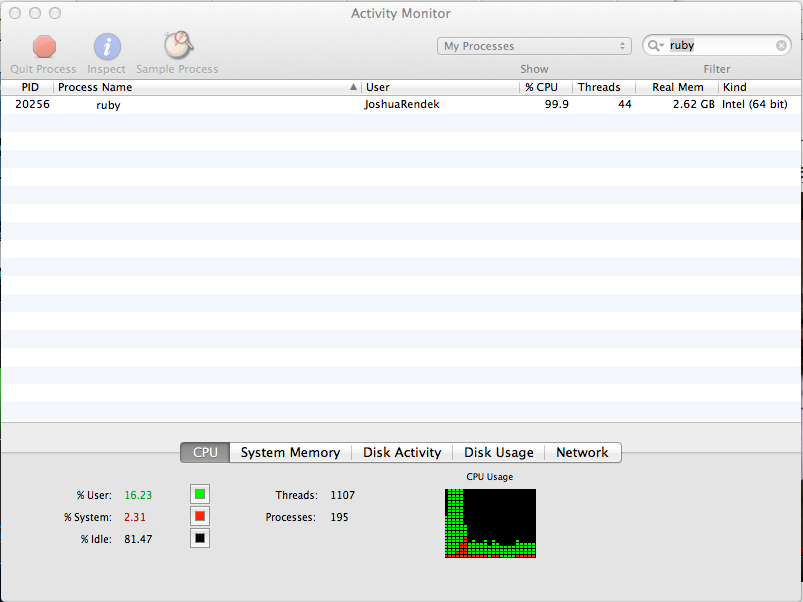
The memory kept growing so I had to kill the process after a few seconds.
Threading with JRuby on the JVM
JRuby specifies the use of native threads based on the operating system support using the getNativeThread call [2]
. JRuby’s implementation of threads using the JVM means there is no GIL/GVL. This allows CPU bound processes to utilize all cores of a machine without having to deal with forking (which, in the case of resque, can be very expensive).
When trying to execute the GIL safe code above JRuby spits out a concurrency error: ConcurrencyError: Detected invalid array contents due to unsynchronized modifications with concurrent users
We can either add a mutex around this code or modify it to not worry about concurrent access. I chose the latter:
1threads = []
2
3objs = {}
4objs['test'] = []
51_000_000.times do
6 objs['test'] << Object.new
7end
8
950.times do |num|
10 threads << Thread.new do
11 1_000_000.times do
12 objs[num] = [] if objs[num].nil?
13 objs[num] << Object.new
14 end
15 end
16end
17
18threads.map(&:join)Compared to the MRI version, ruby running on the JVM was able to make some optimizations and keep memory usage around 800MB for the duration of the test:
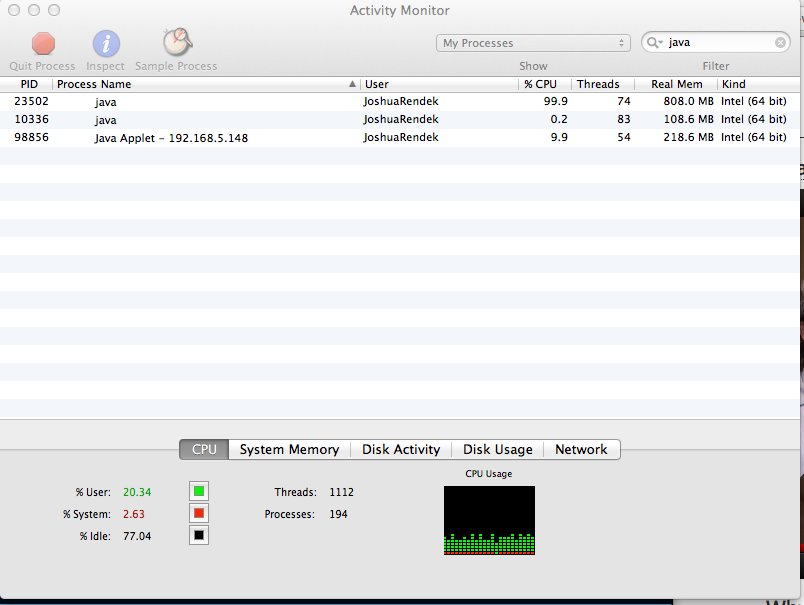
Now that we have a better understanding of the differences between forking and threading in Ruby, lets move on to Sidekiq and Resque.
Sidekiq and Resque
Resque’s view of the world
Resque assumes chaos in your environment. It follows the forking model with C and ruby and makes a complete copy of each resque parent when a new job needs to be run. This has its advantages in preventing memory leaks, long running workers, and locking. You run into an issue with forking though when you need to increase the amount of workers on a machine. You end up not having enough spare CPU cycles since the majority are being taken up handling all the forking.
Resque follows a simple fork and do work model, each worker will take a job off the queue and fork a new process to do the job.
Sidekiq’s view of the world
Unlike Resque, Sidekiq uses threads and is extremely easy to use as a drop in replacement to Resque since they both work on the same perform method. When you dig into the results below you can see that Sidekiq’s claim of being able to handle a larger number of workers and amount of work is true. Due to using threads and not having to allocate a new stack and address space for each fork, you get that overhead back and are able to do more work with a threaded model.
Sidekiq follows the actor pattern. So compared to Resque which has N workers that fork, Sidekiq has an Actor manager, with N threads and one Fetcher actor which will pop jobs off Redis and hand them to the Manager. Sidekiq handles the “chaos” portion of Resque by catching all exceptions and bubbling them up to an exception handler such as Airbrake or Errbit.
Now that we know how Sidekiq and Resque work we can get on to testing them and comparing the results.
The Test Code
The idea behind the test was to pick a CPU bound processing task, in this case SHA256 and apply it across a set of 20 numbers, 150,000 times.
1require 'sidekiq'
2require 'resque'
3require 'digest'
4
5
6# Running:
7# sidekiq -r ./por.rb -c 240
8#
9# require 'sidekiq'
10# require './por'
11# queueing: 150_000.times { Sidekiq::Client.enqueue(POR, [rand(123098)]*20) }
12# queueing: 150_000.times { Resque.enqueue(POR, [rand(123098)]*20) }
13
14class POR
15 include Sidekiq::Worker
16
17 @queue = :por
18
19 def perform(arr)
20 arr.each do |a|
21 Digest::SHA2.new << a.to_s
22 end
23 end
24
25 def self.perform(arr)
26 arr.each do |a|
27 Digest::SHA2.new << a.to_s
28 end
29 end
30
31endTest Machine
1 Model Name: Mac Pro
2 Model Identifier: MacPro4,1
3 Processor Name: Quad-Core Intel Xeon
4 Processor Speed: 2.26 GHz
5 Number of Processors: 2
6 Total Number of Cores: 8
7 L2 Cache (per Core): 256 KB
8 L3 Cache (per Processor): 8 MB
9 Memory: 12 GB
10 Processor Interconnect Speed: 5.86 GT/s
This gives us a total of 16 cores to use for our testing. I’m also using a Crucial M4 SSD
Results
Time to Process 150,000 sets of 20 numbers
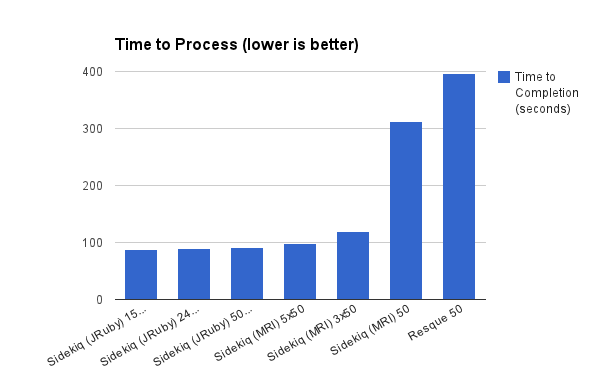
| Type | Time to Completion (seconds) |
| Sidekiq (JRuby) 150 Threads | 88 |
| Sidekiq (JRuby) 240 Threads | 89 |
| Sidekiq (JRuby) 50 Threads | 91 |
| Sidekiq (MRI) 5x50 | 98 |
| Sidekiq (MRI) 3x50 | 120 |
| Sidekiq (MRI) 50 | 312 |
| Resque 50 | 396 |
All about the CPU
Resque: 50 workers
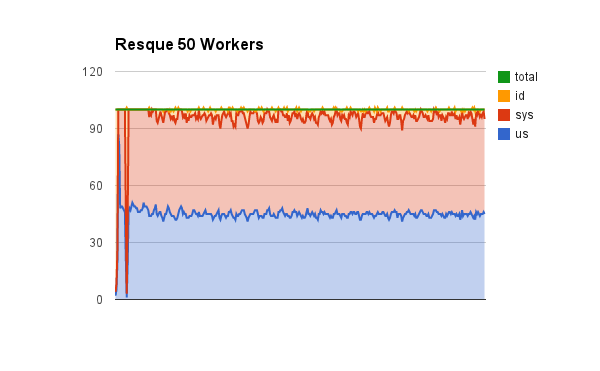
Here we can see that the forking is taking its toll on the available CPU we have for processing. Roughly 50% of the CPU is being wasted on forking and scheduling those new processes. Resque took 396 seconds to finish and process 150,000 jobs.
Sidekiq (MRI) 1 process, 50 threads
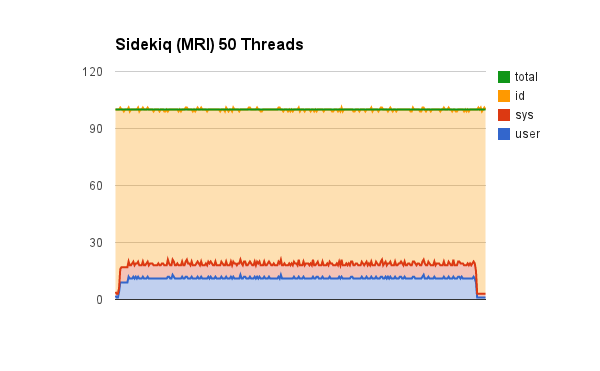
We’re not fully utilizing the CPU. When running this test it pegged one CPU at 100% usage and kept it there for the duration of the test. We have a slight overhead with system CPU usage. Sidekiq took 312 seconds with 50 threads using MRI Ruby. Lets now take a look at doing things a bit resque-ish, and use multiple sidekiq processes to get more threads scheduled across multiple CPUs.
Sidekiq (MRI) 3 processes, 50 threads
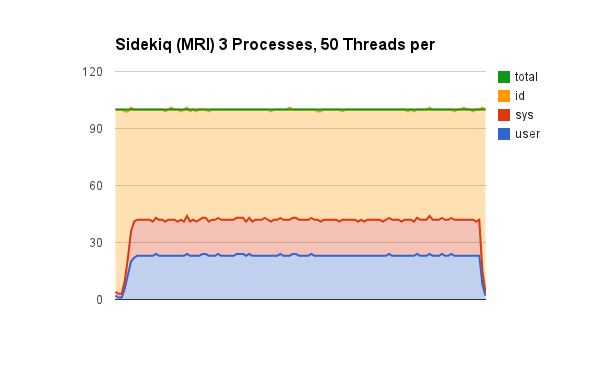
We’re doing better. We’ve cut our processing time roughly in third and we’re utilizing more of our resources (CPUs). 3 Sidekiq processes with 50 threads each (for a total of 150 threads) took 120 seconds to complete 150,000 jobs.
Sidekiq (MRI) 5 processes, 50 threads
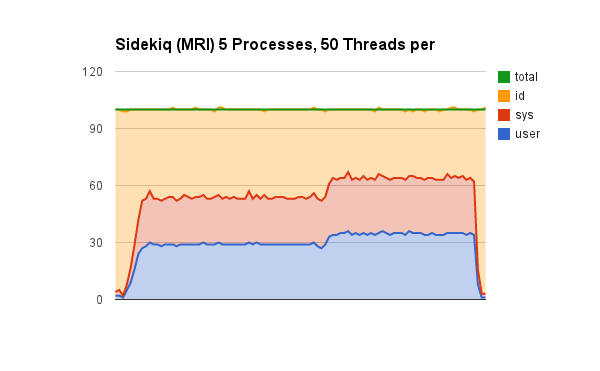
As we keep adding more processes that get scheduled to different cores we’re seeing the CPU usage go up even further, however with more processes comes more overhead for process scheduling (versus thread scheduling). We’re still wasting CPU cycles, but we’re completing 150,000 jobs in 98 seconds.
Sidekiq (JRuby) 50 threads
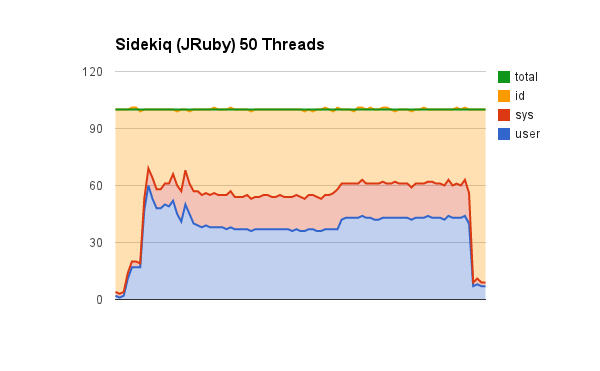
We’re doing much better now with native threads. With 50 OS level threads, we’re completing our set of jobs in 91 seconds.
Sidekiq (JRuby) 150 threads & 240 Threads
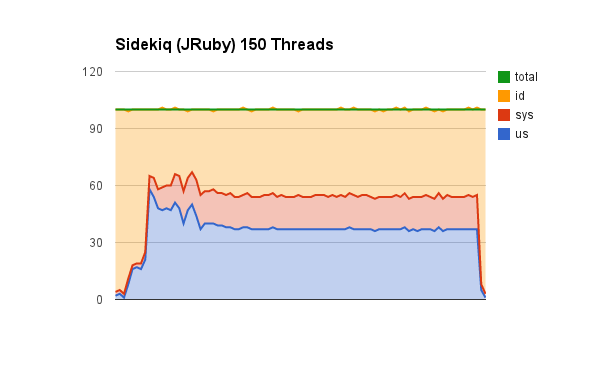
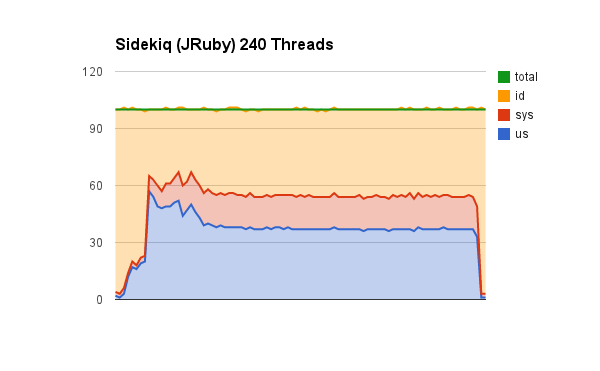
We’re no longer seeing a increase in (much) CPU usage and only a slight decrease in processing time. As we keep adding more and more threads we end up running into some thread contention issues with accessing redis and how quickly we can pop things off the queue.
Overview
Even if we stick with the stock MRI ruby and go with Sidekiq, we’re going to see a huge decrease in CPU usage while also gaining a little bit of performance as well.
Sidekiq, overall, provides a cleaner, more object oriented interface (in my opinion) to inspecting jobs and what is going on in the processing queue.
In Resque you would do something like: Resque.size("queue_name"). However, in Sidekiq you would take your class, in this case, POR and call POR.jobs to get the list of jobs for that worker queue. (note: you need to require 'sidekiq/testing' to get access to the jobs method).
The only thing I find missing from Sidekiq that I enjoyed in Resque was the ability to inspect failed jobs in the web UI. However Sidekiq more than makes up for that with the ability to automatically retry failed jobs (although be careful you don’t introduce race conditions and accidentally DOS yourself).
And of course, JRuby comes out on top and gives us the best performance and bang for the buck (although your mileage may vary, depending on the task).
Further Reading
Deploying with JRuby: Deliver Scalable Web Apps using the JVM (Pragmatic Programmers)