When you work on your code and are finished for the day, is what you have committed worry free? If another developer were to push your code in the middle of the night, would they be calling you at 3am?
Let’s see how we can improve our development cycle with testing so we can avoid those early morning calls. We’ll go over some of the basics with a simple project to start.
The most important part about TDD is getting quick feedback based on our desired design (the feedback loop).
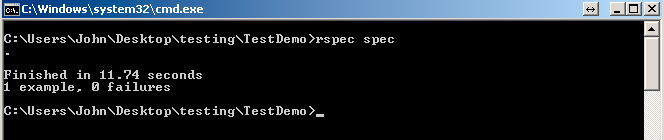
Here is an example of how fast the tests run:
While this is a somewhat contrived example for the reddit cli we’re making, this can be applied equally as well when writing Rails applications. Only load the parts you need (ActionMailer, ActiveSupport, etc), usually you don’t need to load the entire rails stack. This can make your tests run in milliseconds instead of seconds. This lets you get feedback right away.
Before we go further into the testing discussion, lets setup a spec helper.
{% codeblock spec/spec_helper.rb lang:ruby %}
require ‘rspec’
require ‘vcr’
require ‘pry’
VCR.configure do |c|
c.cassette_library_dir = ‘fixtures/vcr_cassettes’
c.hook_into :fakeweb# or :fakeweb
end
{% endcodeblock %}
Now how do we start doing TDD? We first start with a failing test.
{% codeblock Reddit API Spec (Pass 1) - spec/lib/reddit_api_spec lang:ruby %}
require ‘spec_helper’
require ‘./lib/reddit_api’
describe RedditApi do
let(:reddit) { RedditApi.new(‘ProgrammerHumor’) }
context “#initializing” do
it “should form the correct endpoint” do
reddit.url.should eq “http://reddit.com/r/ProgrammerHumor/.json?after="
end
end
end
{% endcodeblock %}
When we create a new instance of the Reddit API we want to pass it a subreddit, and then we want to make sure it builds the URL properly.
{% codeblock Reddit API (Pass 1) - lib/reddit_api.rb lang:ruby %}
require ‘json’
require ‘rest-client’
class RedditApi
REDDIT_URL = “http://reddit.com/r/"
attr_reader :url, :stories
def initialize(subreddit)
@subreddit = subreddit
@after = "”
@url = “#{REDDIT_URL}#{subreddit}/.json?after=#{@after}”
end
end
{% endcodeblock %}
Next we want to make the actual HTTP request to the Reddit api and process it.
{% codeblock Reddit API Spec (Pass 2) - spec/lib/reddit_api_spec lang:ruby %}
require ‘spec_helper’
require ‘./lib/reddit_api’
describe RedditApi do
let(:reddit) { RedditApi.new(‘ProgrammerHumor’) }
context “#initializing” do
it “should form the correct endpoint” do
VCR.use_cassette(‘reddit_programmer_humor’) do
reddit.url.should eq “http://reddit.com/r/ProgrammerHumor/.json?after="
end
end
end
context "#fetching" do
it "should fetch the first page of stories" do
VCR.use_cassette('reddit_programmer_humor') do
reddit.stories.count.should eq(25)
end
end
end
end
{% endcodeblock %}
We’ve now added a VCR wrapper and added an expectation that the reddit api will return a list of stories. We use VCR here to again ensure that our tests run fast. Once we make the first request, future runs will take milliseconds and will hit our VCR tape instead of the API.
Now we need to introduce three new areas: requesting, processing, and a Story object class.
{% codeblock Story - lib/story.rb lang:ruby %}
Story = Struct.new(:title, :score, :comments, :url)
{% endcodeblock %}
{% codeblock Reddit API (Pass 2) - lib/reddit_api.rb lang:ruby %}
require ‘json’
require ‘rest-client’
require ‘./lib/story’
class RedditApi
REDDIT_URL = “http://reddit.com/r/"
attr_reader :url, :stories
def initialize(subreddit)
@subreddit = subreddit
@after = "”
@url = “#{REDDIT_URL}#{subreddit}/.json?after=#{@after}”
request
process_request
end
def request
@request_response = JSON.parse(RestClient.get(@url))
end
def process_request
@stories = []
@request_response['data']['children'].each do |red|
d = red['data']
@stories << Story.new(d['title'], d['score'],
d['num_comments'], d['url'])
end
@after = @request_response['data']['after']
end
end
{% endcodeblock %}
What can we do now? The API lets us make a full request and get a list of Story struct objects back. We’ll be using this array of structs later on to build the CLi.
The only thing left for this simple CLI a way to get to the next page. Let’s add our failing spec:
{% codeblock Reddit API Spec (Pass 3) - spec/lib/reddit_api_spec lang:ruby %}
require ‘spec_helper’
require ‘./lib/reddit_api’
describe RedditApi do
let(:reddit) { RedditApi.new(‘ProgrammerHumor’) }
context “#initializing” do
it “should form the correct endpoint” do
VCR.use_cassette(‘reddit_programmer_humor’) do
reddit.url.should eq “http://reddit.com/r/ProgrammerHumor/.json?after="
end
end
end
context "#fetching" do
it "should fetch the first page of stories" do
VCR.use_cassette('reddit_programmer_humor') do
reddit.stories.count.should eq(25)
end
end
it "should fetch the second page of stories" do
VCR.use_cassette('reddit_programmer_humor_p2') do
reddit.next.stories.count.should eq(25)
end
end
end
end
{% endcodeblock %}
And let’s make the test pass:
{% codeblock Reddit API (Pass 3) - lib/reddit_api.rb lang:ruby %}
require ‘json’
require ‘rest-client’
require ‘./lib/story’
class RedditApi
REDDIT_URL = “http://reddit.com/r/"
attr_reader :url, :stories
def initialize(subreddit)
@subreddit = subreddit
@after = "”
@url = “#{REDDIT_URL}#{subreddit}/.json?after=#{@after}”
request
process_request
end
def next
@url = "#{REDDIT_URL}#{@subreddit}/.json?after=#{@after}"
request
process_request
self
end
def request
@request_response = JSON.parse(RestClient.get(@url))
end
def process_request
@stories = []
@request_response['data']['children'].each do |red|
d = red['data']
@stories << Story.new(d['title'], d['score'],
d['num_comments'], d['url'])
end
@after = @request_response['data']['after']
end
end
{% endcodeblock %}
We also allow method chaining since we return self after calling next (so you could chain next’s for instance).
Another important principal to keep in mind is the “Tell, Dont Ask” rule. Without tests, we might have gone this route:
{% codeblock bad_example.rb lang:ruby %}
@reddit = Reddit.new(‘ProgrammerHumor’)
User presses next
@reddit.url = “http://reddit.com/r/ProgrammerHumor/.json?after=sometoken"
{% endcodeblock %}
Not only would we not be telling the object what we want, we would be modifying the internal state of an object as well. By implementing a next method we abstract the idea of a URL and any tokens we may need to keep track of away from the consumer. Doing TDD adds a little extra step of “Thinking” more about what we want our interfaces to be. What’s easier? Calling next or modifying the internal state?
I’m kind of cheating a bit here. I found a nice “table” gem that outputs what you send in as a formatted table (think MySQL console output). Let’s just make sure everything is being sent around properly and STDOUT is printing the correct contents:
{% codeblock Reddit CLI Spec (Pass 1) - spec/lib/reddit-cli.rb lang:ruby %}
require ‘spec_helper’
require ‘stringio’
require ‘./lib/reddit-cli’
describe RedditCli do
let(:subreddit) { “ProgrammerHumor” }
context “#initializing” do
before(:all) do
$stdout = @fakeout = StringIO.new
end
it "should print out a story" do
api_response = double(RedditApi)
api_response.stub!(:stories =>
[Story.new("StoryTitle", "Score",
"Comments", "URL")])
$stdin.should_receive(:gets).and_return("q")
cli = RedditCli.new(api_response)
$stdout = STDOUT
@fakeout.string.include?('StoryTitle').should be_true
end
end
end
{% endcodeblock %}
We’re doing several things here. First we’re taking $stdout and putting it (temporarily) into a instance variable so we can see what gets outputted. Next we’re mocking out the RedditApi since we dont actually need to hit that class or the VCR tapes, we just need to stub out the expected results (stories) and pass the response object along to the CLI class. And finally once we’re finished we set $stdout back to the proper constant.
And the class for output:
{% codeblock Reddit CLI (Pass 1) - lib/reddit-cli.rb lang:ruby %}
require ‘./lib/reddit_api’
require ’terminal-table’
class RedditCli
def initialize(api)
@rows = []
@api = api
@stories = api.stories
print_stories
print “\nType ? for help\n”
prompt
end
def print_stories
@stories.each_with_index {|x, i| @rows << [i, x.score, x.comments, x.title[0..79] ] }
puts Terminal::Table.new :headings=> ['#', 'Score', 'Comments', 'Title'], :rows => @rows
end
def prompt
print "\n?> "
input = STDIN.gets.chomp
case input
when "?"
p "Type the # of a story to open it in your browser"
p "Type n to go to the next page"
prompt
when "quit", "q"
when "n"
@rows = []
@stories = @api.next.stories
print_stories
prompt
else
print "#=> Oepning: #{@stories[input.to_i].url}"
`open #{@stories[input.to_i].url}`
prompt
end
end
end
{% endcodeblock %}
And finally, a little wrapper in the root directory:
{% codeblock Wrapper - reddit-cli.rb lang:ruby %}
require ‘./lib/reddit_api’
require ‘./lib/reddit-cli’
subreddit = ARGV[0]
RedditCli.new(RedditApi.new(subreddit))
{% endcodeblock %}
An Important Note
When working with external resources, whether it be a gem or a remote API, it’s important to wrap those endpoints in your own abstraction. For instance, with our Reddit CLI we could have avoided those first 2 classes entirely, written everything in the CLI display class, and worked with the raw JSON. But what happens when Reddit changes their API? If this CLI class was huge or incoporated many other components, this could be quite a big code change. Instead, what we wrote encapsulates the API inside a RedditApi class that returns a generic Story struct we can work with and pass around. We don’t care if the API changes in the CLI, or in any other code. If the API changes, we only have to update the one API class to mold the new API to the output we were already generating.
End Result & Source Code





 GitHub
GitHub